
 4006809895
4006809895
 注册/登录
注册/登录
数据编织是一种将多个数据源整合、连接和组合以创建新的数据集或视图的过程。它涉及将具有不同结构和格式的数据进行转换和整合,以便进行更全面、更深入的数据分析和洞察。
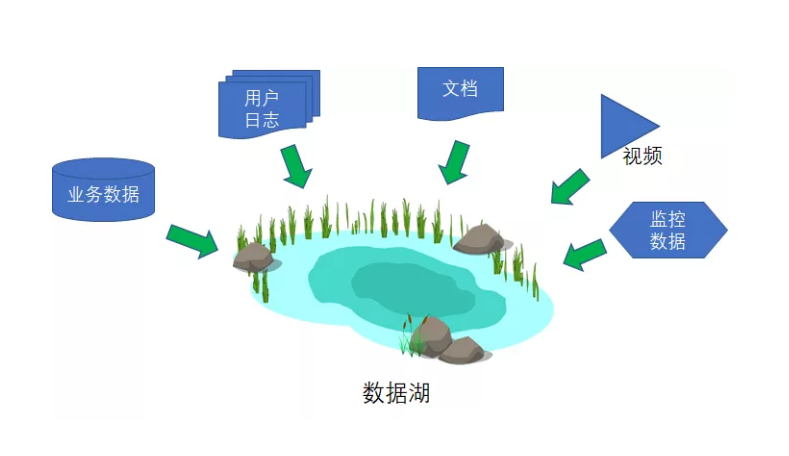
在数据编织过程中,通常包括以下几个步骤:
数据提取:从不同的数据源(如数据库、文件、API等)中提取所需的数据。这些数据源可能具有不同的数据格式和存储结构。
数据清洗:对提取的数据进行清洗和预处理,以消除重复值、缺失值、错误数据和不一致性等问题。这确保了数据的准确性和一致性。
数据转换:将数据从原始格式转换为目标格式。这可能包括数据类型转换、日期时间格式化、单位转换等操作,使得不同数据源的数据可以进行匹配和整合。
数据集成:将来自不同数据源的数据进行连接和合并,创建一个统一的数据集。这样一来,可以通过关联和引用来分析和探索不同数据之间的关系。
数据加工:根据业务需求和分析目的,对整合后的数据进行进一步操作和加工。这可以包括计算衍生指标、生成汇总报告、应用规则或模型等。
数据发布:将编织后的数据集或视图提供给用户或应用程序进行进一步的分析、可视化或决策支持。
数据编织的目标是获得更全面、一致且高质量的数据,以支持更深入的数据分析和洞察。通过将多个数据源整合在一起,企业可以更好地理解客户行为、市场趋势、业务绩效等方面,并做出基于全面数据的明智决策。
举例来说,假设一家零售公司需要综合分析来自不同渠道的销售数据、库存数据和市场活动数据。通过数据编织,他们可以将这些数据源连接和整合在一起,创建一个包含所有关键指标的综合性数据集。这样,该公司就能够深入了解产品的销售情况、库存水平与需求之间的关系,并对市场推广策略进行优化。通过数据编织,这家零售公司可以从整体上了解业务状况,并作出更明智的商业决策。
数据编织在商业智能、金融风险管理、医疗健康管理以及物联网与智能城市等领域都有着重要的应用。随着数据源的不断增加和数据处理技术的不断发展,数据编织将在更多的领域中发挥重要作用,它帮助企业消除数据孤岛,创建一个一致的数据视图,并提供更全面的洞察力,从而支持决策制定和业务增长。


















